
In this paper, we evaluate the impact of extracting intermediate features related to the driver like face-pose, body-pose and presence of different objects on the accuracy of predicting in-cabin activities in the context of autonomous vehicles which ultimately helps in determining if driver is driving safely.
Intro
I am a 2nd year Graduate student at Electronics and Computer Engineering, University of California, San Diego. My area of research lie at the intersection of Planning using Reinforcement Learning, Computer Vision, Autonomous Driving and Deep Learning. Prior to this, I have worked at Microsoft and Uber in Applied Machine Learning products.
Experience
July 2021 - Research Assistant @ Supercomputer Department, UCSD
2018 - 2020 Software Engineer @ Uber
2014 - 2018 Software Engineer @ Microsoft
Education
2010 - 2014 IIIT-A, India
Projects
Autonomous Driving
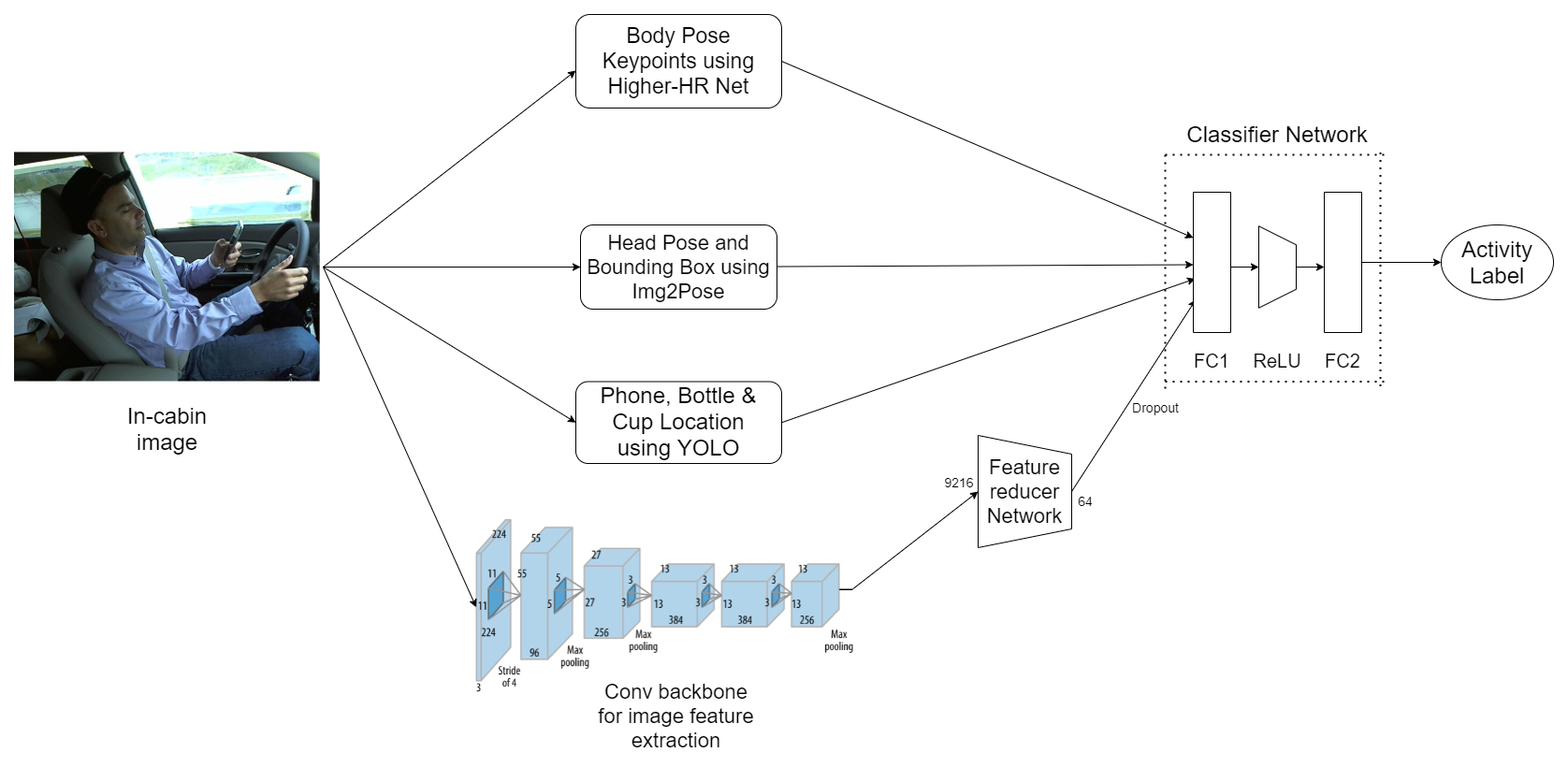
Architecture of Model using Body-pose, Face-pose and Object detection for In-cabin Activity Taxonomy
In-cabin Activity Taxonomy using Body Pose Features

Turn around and park in front of that vehicle in the shade.
Visual Grounding of Objects in Command for Autonomous Vehicles
In this project, we are trying to solve the problem of Visual grounding of the object mentioned via command in the respective image. More specifically, we are targeting scenarios where a passenger can pass free-form natural language commands to a self-driving car.
GAN
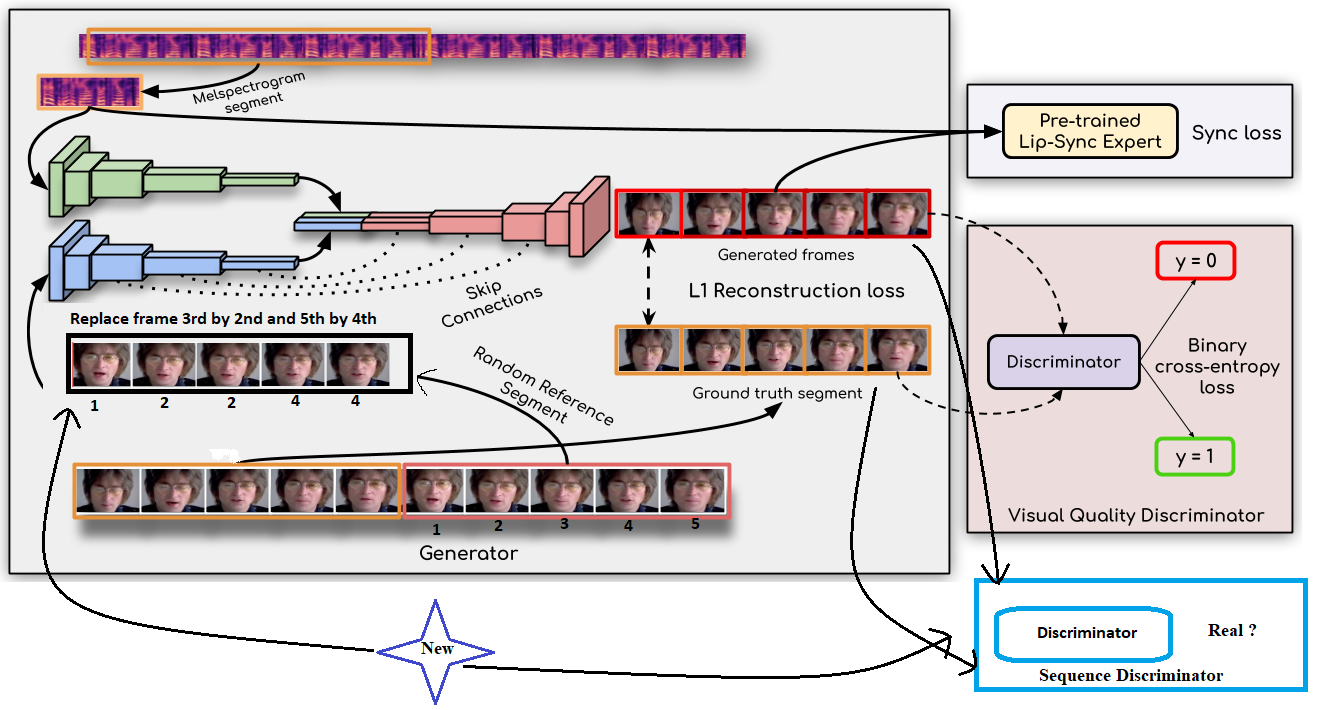
Generative model-based video compression
In this paper, we propose a new method of recovering high-quality video conferencing streams from low frame rate video streams using deep learning. As a baseline, we propose a scheme using existing frame interpolation methods and lip movement generation methods, which we fine-tune to fit our particular use case. Then we introduce Wav2FSS, a novel end-to-end framework capable of generating a high-quality reconstruction of the speaker’s face. When validated against our baseline, this model proves to be state-of-the-art.
Reinforcement Learning
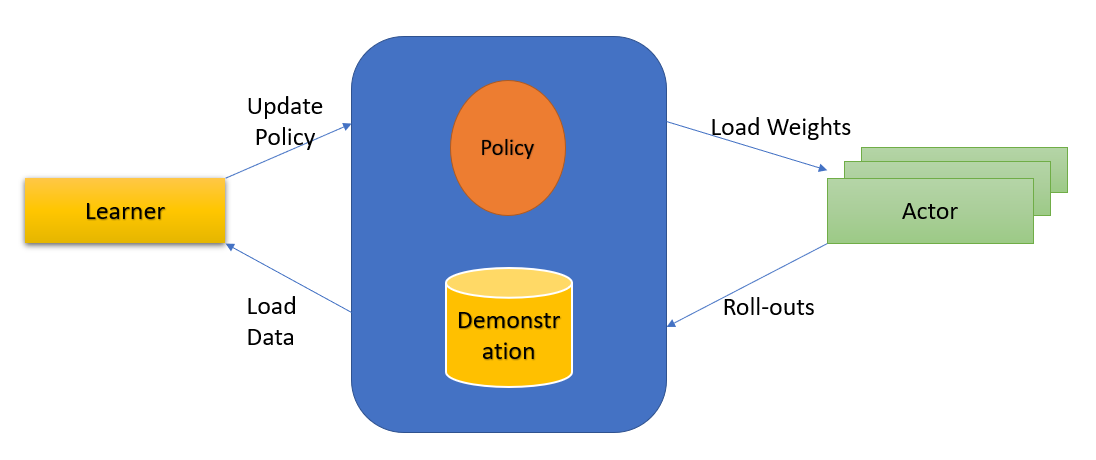
Learn Policy for Google Football Environment using Actor-Critic
In this paper, we implemented Actor-Critic Reinforcement algorithm for learning an agent to play soccer in Google Football environment.
NLP

NER in Synthetic Biology related articles using BERT
In this project, we are developing a model using BERT as bottleneck for NER in Synthetic Biology related articles for entities like Gene, Chemicals, Species, Cellline, etc.
Biology

Cancer Lineage Subtype Classification Using Gene Hierarchy-Based “Visible” Neural Networks on Tumor Mutations
In this paper, we developed a “visible” neural network capable of predicting tumor type and subtype based solely on tumor sequencing data. This model uses the Cancer Dependency Map (DepMap) database, which contains all necessary genetic and cell line information. The model architecture is based upon previously described hierarchy-based networks that connect neurons based on cell process interactions described in the Gene Ontology (GO) Resource, a manually curated database mapping genetic interactions.